本文共 7852 字,大约阅读时间需要 26 分钟。
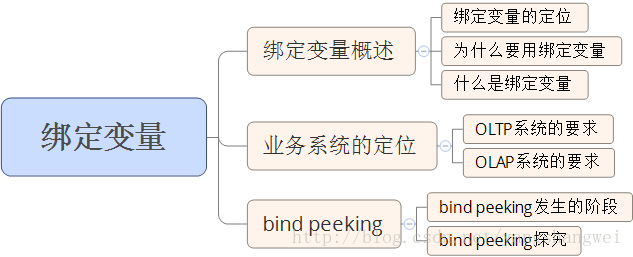
思维导图
系列博文
概述
绑定变量是OLTP系统中一个非常值得关注的技术点。良好的变量绑定会使OLTP系统数据库中的SQL执行的飞快,内存效率极高。 不绑定变量有可能会使OLTP数据库不堪负重,资源被SQL解析严重消耗,系统显得缓慢。
本博文的案例基于Oracle Database 11g Enterprise Edition Release 11.2.0.4.0
SQL究竟是如何被执行的?
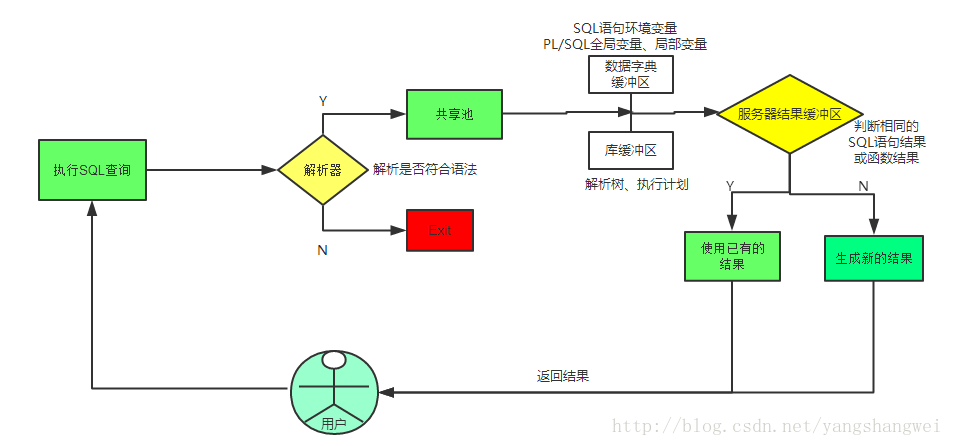
在介绍绑定变量之前,我们需要知道SQL究竟是如何被执行的?
当一个用户与数据库建立连接后,向数据库发送SQL语句,Oracle在接到这条SQL后,首先会将这个SQL做一个Hash函数运算,得到一个Hash值,然后到共享池中寻找是否有和这个hash值匹配的SQL存在。
如果找到了,Oracle会直接使用已经存在的SQL的执行计划去执行当前的SQL,然后将结果返回给用户。
如果没有找到,Oracle会认为这是一条新的SQL, 将会按照下面的顺序来执行:
1 .语法分析
SQL 是否符Oracle规定的语法,如果有语法错误,则向用户抛出错误信息
2. 语义分析
语法分析通过之后,Oracle会对这条SQL做一些对象、权限方面的检查,查看SQL中操作的表是否存在,表中的列是否正确,用户是否有权限操作这个对象的权限等

3 .生成执行计划
这个过程Oracle在经过一些列的操作之后,来做出SQL最后的执行计划,比如查看操作对象的统计信息,动态采样等等。
如何生成执行计划的详细信息,可以参考10053事件
4.执行SQL
Oracle按照上一步生成的执行计划,执行SQL,并将结果返回给用户。
以上的这些工作,我们通常称为硬分析(hard parse),其实是十分消耗系统资源的。 而对于相同Hash值的SQL已经存在于共享池中则称为软分析(soft parse)。
绑定变量 what ,why
绑定变量就起本质而言就是说把本来需要Oracle做硬分析的SQL变成了软分析,以减少Oracle花费在SQL解析上的时间和资源。
是否采用绑定变量在资源消耗上对比
下面我们来对下同一条SQL被执行10000次,绑定变量和非绑定变量在资源消耗上的情况
采用绑定变量
打开SQL_TRACE
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as xx@xgj##打开时间统计SQL> set timing on;##为防止干扰信息,先手动的清空共享池中的信息(若生产环境慎重)SQL> alter system flush shared_pool;System alteredExecuted in 0.078 seconds##建表SQL> create table t as select * from dba_objects; Table createdExecuted in 0.281 seconds##设置trace文件标识SQL> alter session set tracefile_identifier='xgj_var_bind';Session alteredExecuted in 0 seconds##打开SQL_TRACESQL> alter session set sql_trace=true;Session alteredExecuted in 0.015 seconds##执行SQL块SQL> begin 2 for i in 1 .. 10000 loop 3 execute immediate 'select * from t where t.object_id = :i' using i ; 4 end loop; 5 end; 6 /PL/SQL procedure successfully completedExecuted in 0.578 seconds##关闭SQL_TRACESQL> alter session set sql_trace=false ;Session alteredExecuted in 0 secondsSQL>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
对原始trace文件进行tkprof分析汇总
在Oracle服务器端获取到trace文件后,使用tkprof进行分析汇总,查看
oracle@entel1:[/oracle/diag/rdbms/cc/cc/trace]$ls *xgj_var_bind*cc_ora_32363_xgj_var_bind.trc cc_ora_32363_xgj_var_bind.trmoracle@entel1:[/oracle/diag/rdbms/cc/cc/trace]$tkprof cc_ora_32363_xgj_var_bind.trc xgj_var_bind.txt sys=noTKPROF: Release 11.2.0.4.0 - Development on Sat Dec 17 21:13:11 2016Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们截取分析汇总后的关键部分来看
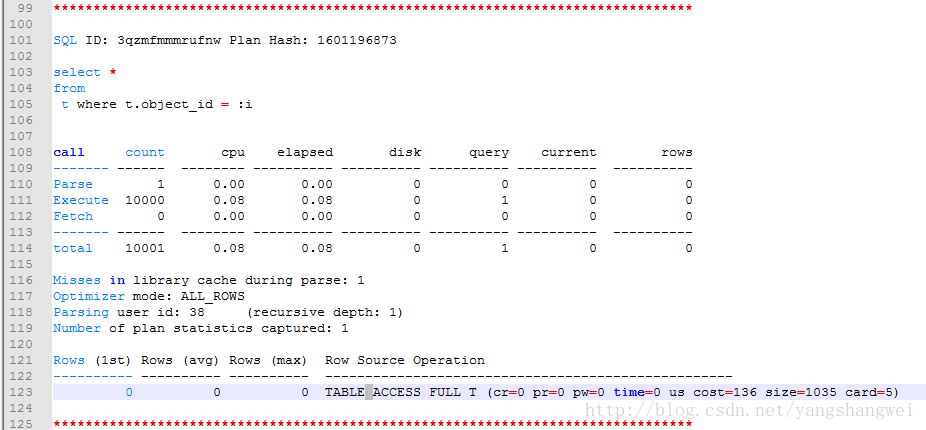
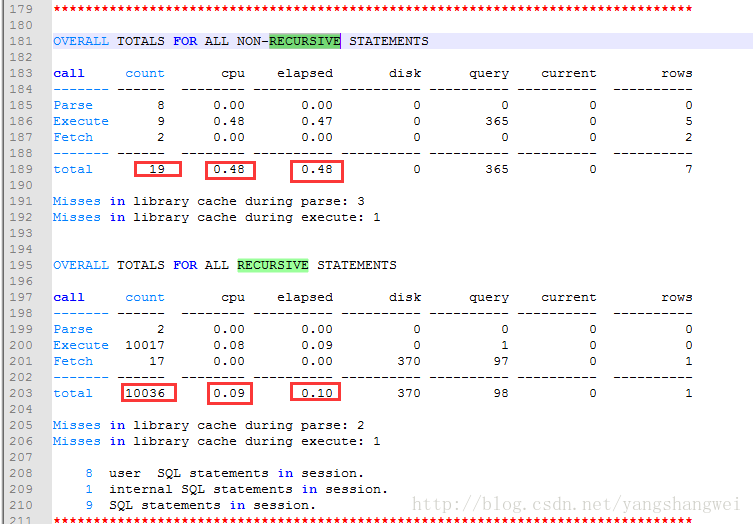
整个过程加上产生的递归SQL,我们可以看到整个语句的:
ALL NON-RECURSIVE STATEMENTS + ALL RECURSIVE STATEMENTS
- 执行时间(elapsed):0.48+0.10 = 0.58 (和刚才输出的时间大致一致)
- CPU时间(cpu):0.48+0.09=0.57
- 分析次数(parse):8+2=10
- 执行次数(execute):9+10017=10025
不采用绑定变量
SQL> set timing on ;SQL> alter session set tracefile_identifier='xgj_var_unbind';Session alteredExecuted in 0.016 secondsSQL> alter session set sql_trace=true;Session alteredExecuted in 0.016 secondsSQL> begin 2 for x in 1 .. 10000 loop 3 execute immediate 'select * from t where t.object_id ='||x; 4 end loop; 5 end; 6 /PL/SQL procedure successfully completedExecuted in 16.672 seconds -----耗时很长SQL>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
执行tkprof分析汇总

查看xgj_var_unbind.txt关键部分
………… 中间省略一万万字
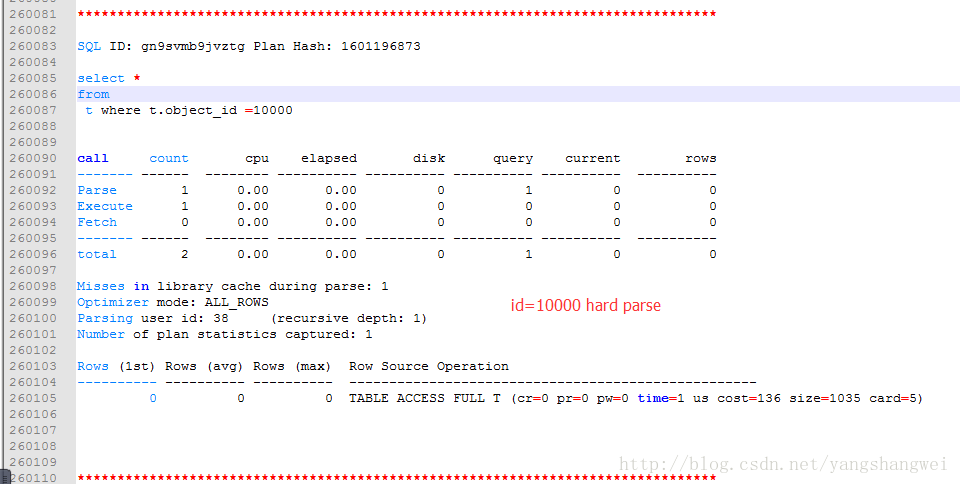
可以看到 每一条都是hard parse,非常消耗系统资源,耗时很长。
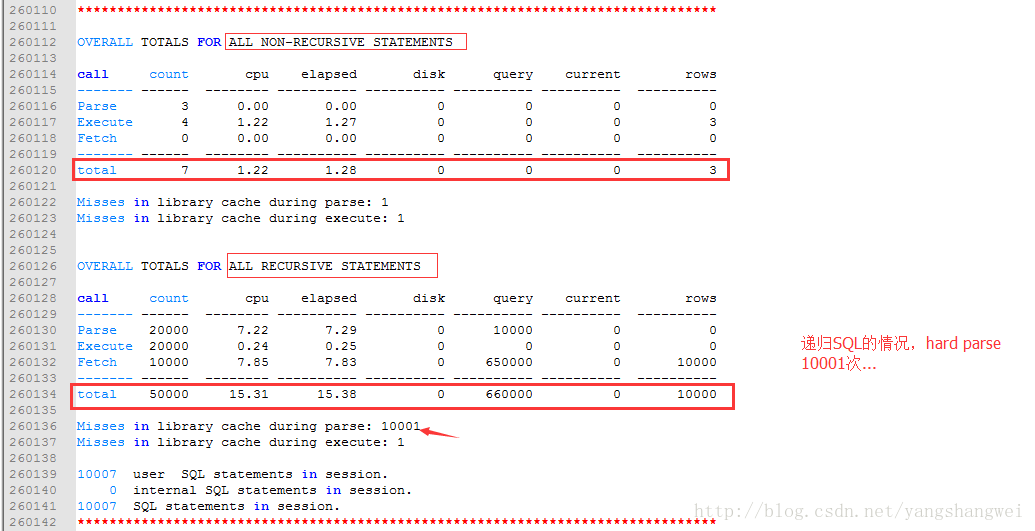
同样的我们统计下执行信息:
ALL NON-RECURSIVE STATEMENTS + ALL RECURSIVE STATEMENTS
- 执行时间(elapsed):1.28+15.38 =16.66
- CPU时间(cpu):1.22+15.31
- 分析次数(parse): 3+20000
- 执行次数(execute):4+20000
通过对比我们可以发现,在OLTP系统中,使用绑定变量的SQL资源消耗要与那远少于未绑定变量SQL的资源消耗,SQL执行的次数越多,差距越明显。
未绑定变量SQL的资源主要消耗在产生的递归SQL上,这些SQL主要是对SQL语句做hard parse时使用的。
试想,当一个数据库有成千上万甚至更多的用户同时执行这样的SQL,而ORACLE只做一次硬分析,后面相同的SQL只执行SQL的执行操作,势必将大大减轻数据库的资源开销。
这就是绑定变量的由来,它并不神秘,不过是拿一个变量来代替谓词常量,让ORACLE每次对用户发送的SQL做hash运算,运算出相同的hash值,于是Oracle便将这些SQL看做同一个SQL对待而已。
OLTP和OLAP系统中是否需要绑定变量分析
如果你使用Oracle的图形化工具DBCA创建数据库,应该有印象,其中有一步是要求你选择数据库的类型是OLTP还是OLAP。 其实这就说明了OLTP和OLAP数据库是有很大的差异的,Oracle需要知道你选择的系统架构,以便于按照系统的架构对相应的参数值做设定,比如初始化参数。
OLTP和OLAP的请参考之前梳理的文章
OLTP栗子
数据:
SQL> drop table t;Table droppedSQL> create table t as select a.OBJECT_ID ,a.OBJECT_NAME from dba_objects a ;Table createdSQL> select count(1) from t; COUNT(1)---------- 35234SQL> 循环300次,写入更多的数据 每50次提交一次数据SQL> begin 2 for i in 1 .. 300 loop 3 execute immediate 'insert into t select a.OBJECT_ID ,a.OBJECT_NAME from dba_objects a'; 4 if mod(i,50)=0 then 5 commit; 6 end if; 7 end loop; 8 end; 9 /PL/SQL procedure successfully completedSQL> select count(1) from t; COUNT(1)---------- 10605434SQL> 在object_id字段上创建索引SQL> create index idx_t on t(object_id);Index created
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
操作步骤
SQL> alter session set tracefile_identifier='xgj_oltp';Session alteredSQL> alter session set sql_trace =true;Session altered执行两遍SQL ##强制走全表扫描执行计划SQL> select /*+ full(t)*/ * from t where object_id = 188; OBJECT_ID OBJECT_NAME---------- --------------------- 188 SQLLOG$_PKEY ........... 301 rows selected##让Oracle自己选择执行计划SQL> select * from t where t.object_id = 188; OBJECT_ID OBJECT_NAME---------- --------------------- 188 SQLLOG$_PKEY ........... 301 rows selectedSQL> alter session set sql_trace=false;Session altered
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
tkprof汇总分析
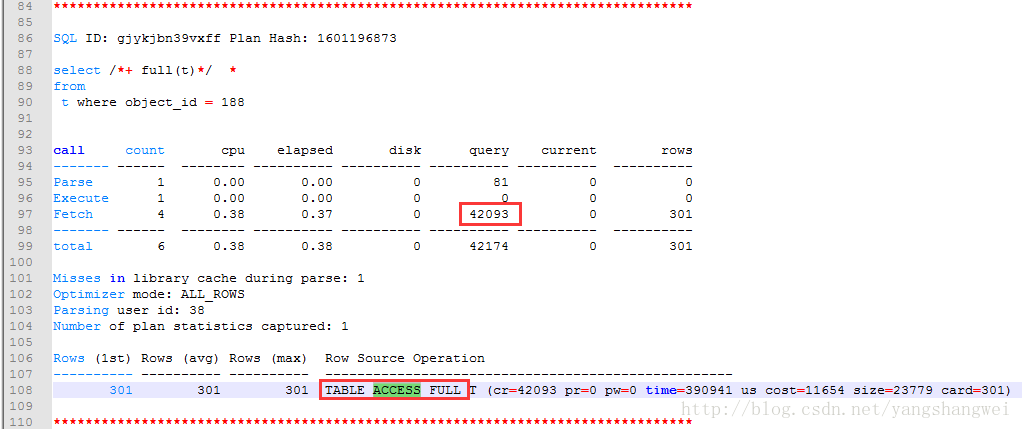
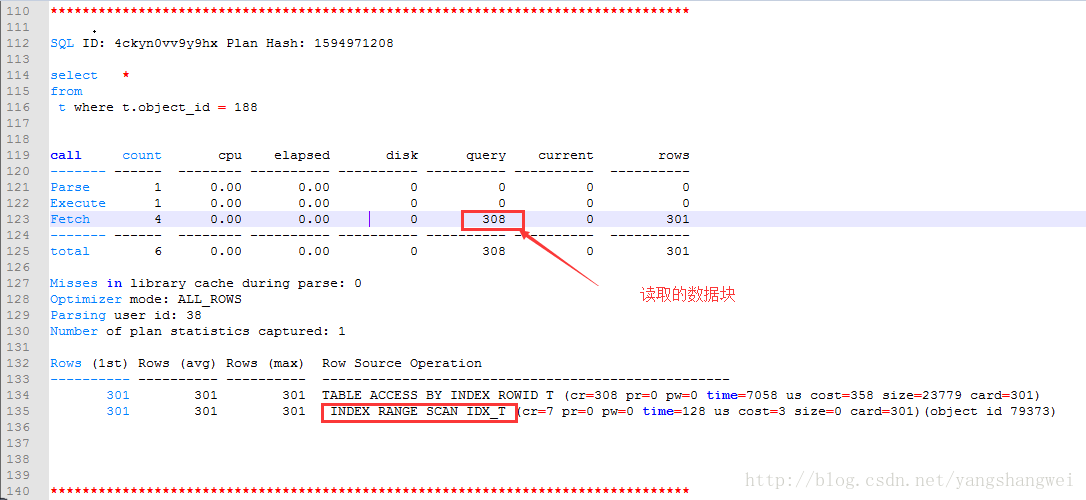
可以看到 全表扫描执行计划的SQL扫描过的数据块明显大于使用索引执行的SQL计划。
从trace文件中可以看到,在fetch阶段,全表扫描读取了42093多个数据块,而走索引的,在fetch阶段,仅仅读取了308个数据块。
OLAP栗子
OLAP系统在SQL的操作中就复杂的多,OLAP数据库上大多数的时候运行是一些报表SQL,这些SQL经常会用到聚合查询(比如group by),而且结果集也是非常庞大,在这种情况下,索引并不是必然的选择,甚至有些时候全表扫描的性能会由于索引,即使相同的SQL,如果谓词条件不同,执行计划都可能不同
数据
SQL> create table t2(object_id, object_name) partition by range (object_id) 2 (partition p1 values less than (5000), 3 partition p2 values less than (15000), 4 partition p3 values less than (25000), 5 partition p4 values less than (maxvalue)) 6 as select object_id, object_name from dba_objects;Table createdSQL> SQL> begin 2 for x in 1 .. 300 loop 3 insert into t2 select object_id ,object_name from dba_objects ; 4 if mod(x,50)=0 then 5 commit; 6 end if; 7 end loop; 8 end; 9 /PL/SQL procedure successfully completedSQL> select count(1) from t2; COUNT(1)---------- 10609046SQL> select count(1) from t2 partition(p1); COUNT(1)---------- 1504097SQL> select count(1) from t2 partition(p2); COUNT(1)---------- 2691241SQL> select count(1) from t2 partition(p3); COUNT(1)---------- 0SQL> select count(1) from t2 partition(p4); COUNT(1)---------- 6413708SQL> 在分区表上建立本地索引SQL> create index idx_t_id on t2(object_id) local;Index created##对表做一次分析(cascade => true ,索引也会被一同分析)SQL> exec dbms_stats.gather_table_stats(user,'t2',cascade => true);PL/SQL procedure successfully completed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
操作步骤
我们使用如下命令
注释:以上的命令,是在plsql客户端执行的,可以支持, 但是autotrace命令,plsql并没有很好的支持,所以我登录到了服务器所在的主机执行的,当然也可以通过sqlplus客户端操作。
SQL> set autotrace traceonly explain ;
- 1
- 2
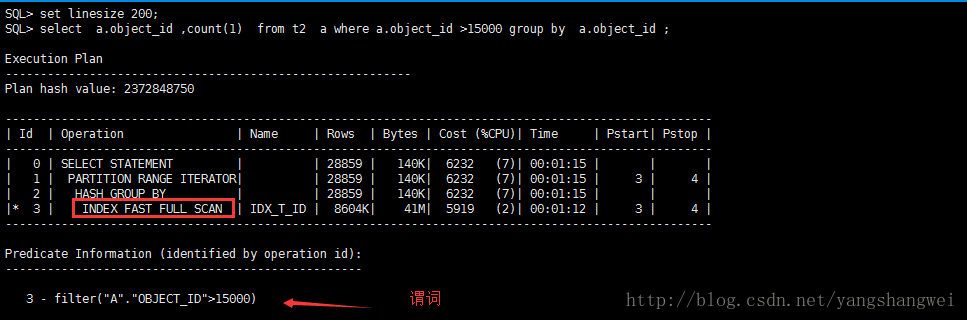
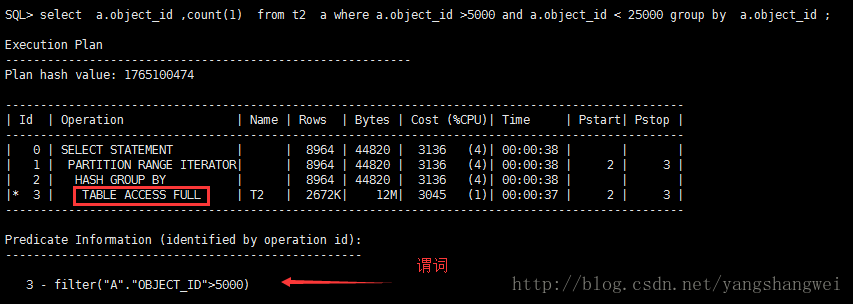
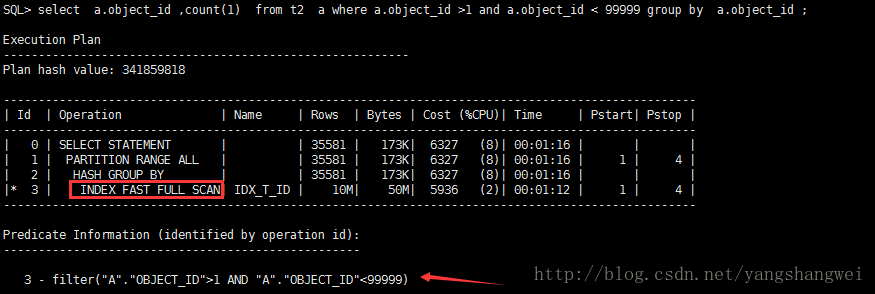
从结果中我们可以看到,虽然只是谓词的不同,但是oracle却选择了不同的执行计划,因为Oracle认为那样的计划代价最小。
结论
- OLAP系统完全没有必要设置绑定变量那样只会带来负面的影响,比如导致SQL选择了错误的执行计划,让Oracle对每条SQL做hard parse ,确切知道谓词条件的值,这对执行计划的选择至关重要。 这是因为在OLAP系统中,SQL硬分析的代价是可以忽略的,系统的资源基本上是用于做大的SQL查询,和查询比较起来,SQL解析消耗的资源显然微不足道,所以得到一个最优的执行计划变得尤为重要
- 在OLAP系统上,让Oracle确切知道谓词条件的值,它直接决定了SQL执行计划的选择,这样做的方式就是不要绑定变量
- 在OLAP系统中,表索引的分析显得至关重要,因为它是Oracle为SQL做出正确的执行计划的信息来源和一句。
bind peeking
谈到变量绑定,我们不得不提一下从Oracle9i开始引入的一个新的特性,叫做bind peaking ,顾名思义,就是在SQL语句硬解析的时候,Oracle会看一下当前SQL谓词的值,以便于生成最佳的执行计划。
需要强调的是,bind peaking 只发生在hard parse的时候,即SQL被第一次执行的时候,之后的变量将不会再做peeking.
bind peeking 并不能最终解决不同谓词导致不同执行计划的问题,它只能让SQL第一次执行的时候,执行计划更加准确,并不能帮助OLAP系统解决绑定变量导致执行计划选择错误的问题,所以,OLAP依然不应该使用绑定变量。
对于OLTP系统来讲,相同的SQL重复频率非常搞,如果优化器范湖解析SQL,势必极大地消耗资源。 另外OLTP系统用户请求的结果通常都是非常小,说基本上都会考虑使用索引。 bind peeking在第一次hard parse的时候获得了一个正确的执行计划,后面的SQL都按照这个计划来执行,可以极大地改善系统的性能,这是由OLTP系统的特性决定的。